WHAT DOES THAT MEAN
https://nature.com/articles/s43588-022-00281-6
https://creativemachineslab.com/hidden-variables.html
https://iflscience.com/an-ai-may-have-just-invented-alternative-physics
AI shown videos of physical phenomena, instructed to identify variables
by Stephen Luntz / Jul 27, 2022
“Our physics is based on variables, such as acceleration and mass. Some of these can be reduced to more fundamental variables, like distance and time. If there is another way to quantify the workings of the universe, we haven’t yet grasped it. However, the variables we are familiar with may not be the only ones, as Columbia roboticists just found out. Dr Boyuan Chen and co-authors trained an artificial intelligence (AI) system to count the number of variables needed to describe physical systems and predict developments.

“Hidden variables of double pendulum plotted against each other.
We don’t yet understand what they mean.”
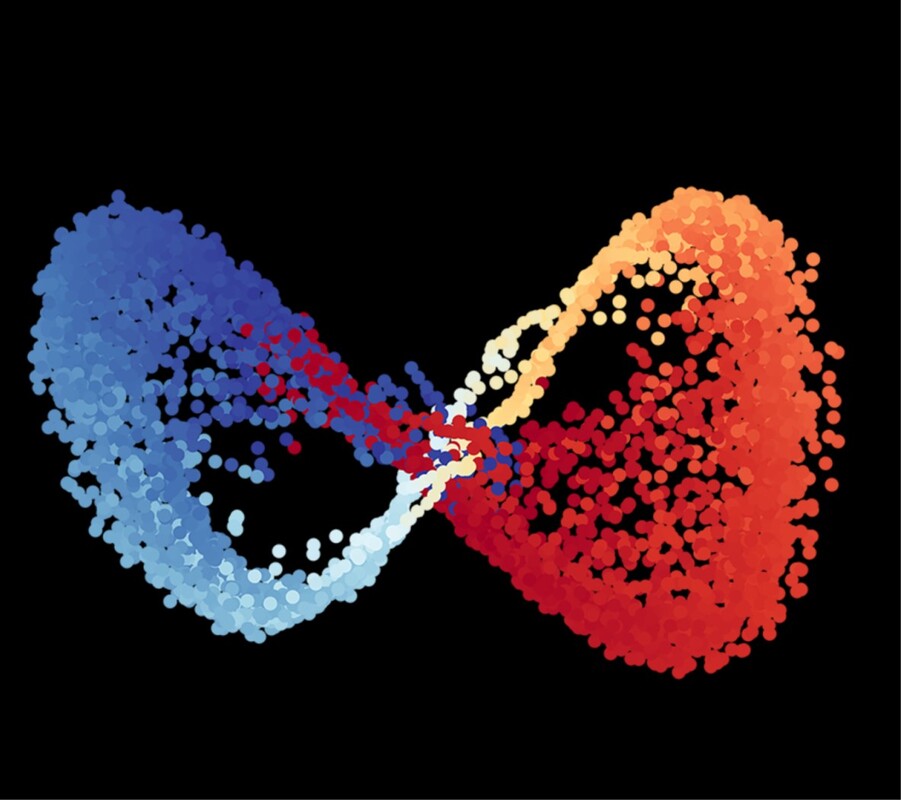
The results have been reported in Nature Computational Science, but this is just the beginning, as we are only starting to understand the variables the computers deduced. “I always wondered, if we ever met an intelligent alien race, would they have discovered the same physics laws as we have, or might they describe the universe in a different way?” said senior author Professor Hod Lipson in a statement. “Perhaps some phenomena seem enigmatically complex because we are trying to understand them using the wrong set of variables.”
Arxiv vs snarxiv is an online game that lets you guess whether you are looking at a real or randomly generated physics paper title.
No matter how much of an expert you believe you are, *everyone* is bad at this!
By @davidsd (since 2010!)https://t.co/olceW3hbXT
— Martin Bauer (@martinmbauer) August 7, 2022
After all, the paper notes: “It took civilizations millennia to formalize basic mechanical variables such as mass, momentum, and acceleration. Only once these notions were formalized could laws of mechanical motion be discovered.” Similarly, you can’t derive the laws of thermodynamics without formal concepts of temperature, energy, and entropy. At least some of these are now intuitive to us, but they weren’t to our ancestors.
Occasionally scientists get a small glimpse of how the universe would look if we started with different variables. Mathematician Norman Wildberger created what he calls “rational trigonometry” by replacing the familiar variables in triangles – length and angle – with squares of the length and sine of the angle, which he calls quadrance and spread. Some problems become much easier when tackled with these variables, but to anyone trained in Euclidean geometry it at first feels like speaking a foreign language. Some cultures – most famously the native American Hopi – are also claimed to view variables such as time differently from most of the rest of the world, giving them a fundamentally different view of physics.
To find variables even more alien to us we would need to consult someone raised with no exposure to familiar concepts like angle and distance. It being illegal to bring up a child like this, the authors turned to AI, starting with a video of elastic double pendulums. A physicist looking at a double pendulum system most likely sees four variables – the angle and angular velocity of each arm. The four are intuitive to us and easily measured. However, undergraduate physics students are trained to also model the system in terms of each arm’s kinetic and potential energy.
The authors showed a neural network a video of a double pendulum and asked it how many state variables it saw. Although the answer was four, the computer and the humans lacked the common language to establish what these variables were. Two appear to be similar to the way we measure arm angles, but the others remain a puzzle. “We tried correlating the other variables with anything and everything we could think of: angular and linear velocities, kinetic and potential energy, and various combinations of known quantities,”explained Chen. “But nothing seemed to match perfectly.”
However, the network predicted the pendulum’s future movements so well it seems it had identified real variables, even if they are strange to us. The authors followed up by showing the computer much more complex dynamical systems, such as an “air dancer” outside a nearby car dealer, a lava lamp, and flames in a fireplace. It reported there were respectively eight, eight, and 24 state variables required to describe these systems, but what these are no one yet knows.
Previous machine learning tools have modeled the dynamics of physical systems but were provided with measurements of relevant state variables, that is quantitative variables that fully describe the system as it evolves. Once taught in this way, the machines were unlikely to come up with alternative variables of their own. Now it seems AI systems can indeed identify new variables – we just need a translator to understand what they are.”
AI program predicts what 'last' selfies on Earth will look like https://t.co/bIXvdGHO4z pic.twitter.com/T3mOO9dTgu
— New York Post (@nypost) July 31, 2022
EXPLAINABLE AI
https://wired.com/dall-e-2-ai-text-image-bias-social-media/
https://technologyreview.com/ai-robots-take-over-warehouses
https://bloomberg.com/how-ai-is-giving-real-world-streets-a-virtual-makeover
https://newscientist.com/ai-predicts-crime-week-in-advance-with-90-accuracy
https://newscientist.com/deepmind-develops-policy-distributing-public-money
DeepMind’s AI develops popular policy for distributing public money
Could artifical intelligence make better funding decisions than senators?
“A “democratic” AI system has learned how to develop the most popular policy for redistributing public money among people playing an online game. “Many of the problems that humans face are not merely technological, but require us to coordinate in society and in our economies for the greater good,” says Raphael Koster at UK-based AI company DeepMind. “For AI to be able to help, it needs to learn directly about human values.” The DeepMind team trained its artificial intelligence to learn from more than 4000 people as well as from computer simulations in an online, four-player economic game. In the game, players start with different amounts of money and must decide how much to contribute to help grow a pool of public funds, eventually receiving a share of the pot in return. Players also voted on their favourite policies for doling out public money.
N 8th St (Sheboygan, Wisconsin) https://t.co/oxEnpo9bAL pic.twitter.com/5iFExHRhGJ
— Will Davis – ??/acc (@wlldvs) July 26, 2022
The policy developed by the AI after this training generally tried to reduce wealth disparities between players by redistributing public money according to how much of their starting pot each player contributed. It also discouraged free-riders by giving back almost nothing to players unless they contributed approximately half their starting funds. This AI-devised policy won more votes from human players than either an “egalitarian” approach of redistributing funds equally regardless of how much each person contributed, or a “libertarian” approach of handing out funds according to the proportion each person’s contribution makes up of the public pot. “One thing we found surprising was that the AI learned a policy that reflects a mixture of views from across the political spectrum,” says Christopher Summerfield at DeepMind.
Also, if you're interested in the ethical questions of artificially intelligent art I put together a small thread. I think there are really interesting questions about labor theory for this sort of stuff, especially if you are any kind of leftisthttps://t.co/HeRdA94uhn
— Abdul Malik, WGC (@MarxGasol) July 31, 2022
When there was the highest inequality between players at the start, a “liberal egalitarian” policy – which redistributed money according to the proportion of starting funds each player contributed, but didn’t discourage free-riders – proved as popular as the AI proposal, by getting more than 50 per cent of the vote share in a head-to-head contest. The DeepMind researchers warn that their work doesn’t represent a recipe for “AI government”. They say they don’t plan to build AI-powered tools for policy-making. That may be as well, because the AI proposal isn’t necessarily unique compared with what some people have already suggested, says Annette Zimmermann at the University of York, UK. Zimmermann also warned against focusing on a narrow idea of democracy as a “preference satisfaction” system for finding the most popular policies. “Democracy isn’t just about winning, about getting whatever policy you like best implemented – it’s about creating processes during which citizens can encounter each other and deliberate with each other as equals,” says Zimmermann.
good news! I typed "human anatomy" into DALL-E and can safely report that the robots have no idea how we work pic.twitter.com/9galaQ3KgK
— Rob DenBleyker (@RobDenBleyker) July 30, 2022
The DeepMind researchers do raise concerns about an AI-powered “tyranny of the majority” situation in which the needs of people in minority groups are overlooked. But that isn’t a huge worry among political scientists, says Mathias Risse at Harvard University. He says modern democracies face a bigger problem of “the many” becoming disenfranchised by the small minority of the economic elite, and dropping out of the political process altogether. Still, Risse says the DeepMind research is “fascinating” in how it delivered a version of the liberal egalitarianism policy. “Since I’m in the liberal-egalitarian camp anyway, I find that a rather satisfactory result,” he says.
Journal reference: Nature Human Behaviour, DOI: 10.1038/s41562-022-01383-x
BLACK BOX MACHINE LEARNING
https://computing.mit.edu/news/physics-and-the-machine-learning-black-box
https://engineering.stanford.edu/peek-inside-black-box-machine-learning-systems
https://bdtechtalks.com/black-box-ai-models/
The dangers of trusting black-box machine learning
by Ben Dickson / July 27, 2020
“Last November, Apple ran into trouble after customers pointed out on Twitter that its credit card service was discriminating against women. David Heinemeir Hansson, the creator of Ruby on Rails, called Apple Card a sexist program. “Apple’s black box algorithm thinks I deserve 20x the credit limit [my wife] does,” he tweeted. The success of deep learning in the past decade has increased interest in the field of artificial intelligence. But the rising popularity of AI has also highlighted some of the key problems of the field, including the “black box problem,” the challenge of making sense of the way complex machine learning algorithms make decisions. The Apple Card disaster is one of many manifestations of the black-box problem coming to light in the past years.
The increased attention to black-box machine learning has given rise to a body of research on explainable AI. And a lot of the work done in the field involves developing techniques that try to explain the decision made by a machine learning algorithm without breaking open the black box. But explaining AI decisions after they happen can have dangerous implications, argues Cynthia Rudin, professor of computer science at Duke University, in a paper published in the Nature Machine Intelligence journal. “Rather than trying to create models that are inherently interpretable, there has been a recent explosion of work on ‘explainable ML’, where a second (post hoc) model is created to explain the first black box model. This is problematic. Explanations are often not reliable,” Rudin writes. and can be misleading, as we discuss below. Such practices can “potentially cause great harm to society,” Rudin warns, especially in critical domains such as healthcare and criminal justice. Instead, developers should opt for AI models that are “inherently interpretable” and “provide their own explanations” Rudin discusses in her paper. And contrary to what some AI researchers believe, in many cases, interpretable models can produce results that are just as accurate as black-box deep learning algorithms.
Two types of black-box AI
Like many things involving artificial intelligence, there’s a bit of confusion surrounding the black-box problem. Rudin differentiates between two types of black-box AI systems: functions that are too complicated for any human to comprehend, and functions that are proprietary. The first kind of black-box AI includes deep neural networks, the architecture used in deep learning algorithms. DNNs are composed of layers upon layers of interconnected variables that become tuned as the network is trained on numerous examples. As neural networks grow larger and larger, it becomes virtually impossible to trace how their millions (and sometimes, billions) of parameters combine to make decisions. Even when AI engineers have access to those parameters, they won’t be able to precisely deconstruct the decisions of the neural network.

“Deep neural networks are composed of several stacked layers of artificial neurons”
The second type of black-box AI, the proprietary algorithms, is a reference to companies who hide the details of their AI systems for various reasons, such as intellectual property or preventing bad actors from gaming the system. In this case, the persons who created the AI system might have knowledge of its inner logic, but the people who use them don’t. We interact will all kinds of black-box AI systems every day, including Google Search’s ranking algorithm, Amazon’s recommendation system, Facebook’s Newsfeed, and more. But the more dangerous ones are those that are being used to hand out prison sentences, determine credit scores, and make treatment decisions in hospitals. While a large part of Rudin’s paper addresses the dangers of neural network black boxes, she also discusses the implications of walled-garden systems that keep their details to themselves.
We need to get one more thing out of the way before we dive deeper into the discussion. Most mainstream media outlets covering AI research use the terms “explainable AI” and “interpretable AI” interchangeably. But there’s a fundamental difference between the two. Interpretable AI are algorithms that gives a clear explanation of their decision-making processes. Many machine learning algorithms are interpretable. For instance, decision trees and linear regression models describe associate coefficients to each of the features of their input data. You can clearly trace the path that your input data takes when it goes through the AI model.

“Decision trees provide clear explanations of their reasoning process”
In contrast, explainable AI are tools that apply to algorithms that don’t provide a clear explanation of their decisions. Researchers, developers, and users rely on these auxiliary tools and techniques to make sense of the logic used in black-box AI models. For instance, in deep learning–based image classifiers, researchers develop models that create saliency maps that highlight the pixels in the input image that contributed to the AI’s output. But the explanation model does not necessarily provide a breakdown of the inner logic of the AI algorithm it investigates. “Explanation here refers to an understanding of how a model works, as opposed to an explanation of how the world works,” Rudin writes in her paper.

“Examples of saliency maps produced by RISE”
“Recent work on the explainability of black boxes—rather than the interpretability of models—contains and perpetuates critical misconceptions that have generally gone unnoticed, but that can have a lasting negative impact on the widespread use of ML models in society,” Rudin warns. A popular belief in the AI community is that there’s a tradeoff between accuracy and interpretability: At the expense of being uninterpretable, black-box AI systems such as deep neural networks provide flexibility and accuracy that other types of machine learning algorithms lack.

“There’s a general belief in the AI community that more complex models result in better performance”
But this really depends on the problem domain, the kind of data available, and the desired results. “When considering problems that have structured data with meaningful features, there is often no significant difference in performance between more complex classifiers and much simpler classifiers after preprocessing,” Rudin notes. In her paper, Rudin also observes that in some cases, the interpretability provided by a simpler machine learning model is more valuable than the marginal performance gained from applying a black-box AI system. “In those cases, the accuracy/interpretability trade-off is reversed — more interpretability leads to better overall accuracy, not worse,” she writes.
This is especially true in critical domains such as medicine, where physicians need to know the logic behind an AI-made decision and apply their own insights and opinion to it. Part of the problem stems from a culture that has pervaded the AI community in the wake of the rise in popularity of deep learning. Many researchers are gravitating toward the “bigger is better” approach, in which there’s hope that bigger deep learning models with more layers and parameters and trained on larger data sets will result in breakthroughs in artificial intelligence. This has led to the vast application of deep learning in domains where interpretable AI techniques can provide equally accurate results. “The belief that there is always a trade-off between accuracy and interpretability has led many researchers to forgo the attempt to produce an interpretable model. This problem is compounded by the fact that researchers are now trained in deep learning, but not in interpretable ML,” Rudin writes.
Explainability methods usually measure how changes to an AI system’s inputs modify its output without peeking inside it. For instance, in the case of an image classifier, researchers make small changes to pixel values and observe how those changes affect the class the AI detects. Based on these observations, they provide a heat map that shows which pixels (or features, in machine learning jargon) are more relevant to the AI. In her paper, Rudin argues that explainability methods do not necessarily provide insights into how the black-box AI model works. “Explanation models do not always attempt to mimic the calculations made by the original model,” Rudin writes. “Rather than producing explanations that are faithful to the original model, they show trends in how predictions are related to the features.”
This can lead to erroneous conclusions about black-box AI systems and explainability methods. For instance, an investigation into a black-box recidivism AI system found that the software was racially biased. But the method the researchers used to explain the AI’s decisions was a linear model that depended on race while the recidivism system in question was a complicated, nonlinear AI system. While the investigation did shed light on the need for transparency in AI systems that make critical decisions, it did not provide an accurate explanation of how the targeted system worked. For all we know, there might have been many more problematic correlations in the AI that the investigation did not unearth.
The problems of AI explanation techniques are also visible in saliency maps for computer vision systems. Most of these techniques will highlight which parts of an image led an image classifier to output a label. But the saliency map for one label does not provide enough information about how the AI system is using the data. For instance, in the following image, the saliency map provided by for the “Siberian husky” and “transverse flute” are oddly similar. This shows that while the classifier is focusing on the right part for the husky photo, there’s no evidence that it is detecting the right features. Rudin warns that this kind of practice can mislead users into thinking the explanation is useful. “Poor explanations can make it very hard to troubleshoot a black box,” she writes. Finally, Rudin notes that not only explainability techniques don’t solve the problem of investigating the overly complicated black-box AI, but further exacerbate the problem by giving us two systems to troubleshoot: The original AI model and the explanability tool.

“Saliency-map explanations do not provide accurate
representations of how black-box AI models work.”
There are many cases where companies hide the details of their AI systems for commercial reasons, such as keeping the edge over their competitors. But the problem with this business model is that while it maximizes the profit of the company developing the AI system, it does nothing to minimize the harm and damage it does to the end user, such as a prisoner getting an excessively long sentence or a needy person being refused their loan.
“There is a conflict of responsibility in the use of black box models for high-stakes decisions: the companies that profit from these models are not necessarily responsible for the quality of individual predictions,” Rudin writes. This trend is especially worrying in areas such as banking, health care, and criminal justice. There’s already a body of work and research on algorithmic bias and AI systems that discriminate against certain demographics. But when the algorithms are kept behind walled gardens and only accessible to their developers, there’s little opportunity for impartial investigation into their inner-workings and most researchers must rely on flawed black-box explanation methods that map inputs to outputs.
Another argument that tech companies often make to defend black-box AI systems is to prevent malicious actors from reverse-engineering and gaming their algorithms. Rudin also refutes this argument. “The reason a system may be gamed is because it most likely was not designed properly in the first place,” she writes, adding that transparency could in fact help improve a system by revealing its flaws. This is an approach that is being embraced in other fields of software engineering. An example is the security, where open source and transparency are increasingly replacing the “security by obscurity” culture where companies hope that hiding the details of their software will keep them secure.
There’s no reason for the AI community not to support the same approach. While black-box AI systems often cost a fortune to develop and train, they are usually more accessible than the domain expertise and talent required to develop interpretable AI. This is why many companies opt to use deep learning systems that are trained on large datasets instead of putting effort into creating interpretable systems. But, Rudin notes, “for high-stakes decisions, analyst time and computational time are less expensive than the cost of having a flawed or overly complicated model.” Companies that have experienced the backlash of their black-box AI systems making unexpected, disastrous decisions can attest to that.
To encourage the development of more interpretable AI systems, Rudin proposes regulation that prevents companies from deploying black-box models where an interpretable model can solve the same problem. “The onus would then fall on organizations to produce black box models only when no transparent model exists for the same task,” Rudin writes. An alternative is to organizations that introduce black box models to report the accuracy of interpretable modelling methods. “In that case, one could more easily determine whether the accuracy/interpretability trade-off claimed by the organization is worthwhile,” Rudin writes. In her paper, Rudin lays out technical details on some of the pathways that can improve the accuracy and development of interpretable AI models in different domains. A very interesting example is deep learning systems that can provide explanations of their decisions in terms of high-level features instead of pixel-by-pixel heat maps.

“New research shows that deep learning models can provide feature-based explanations
of their decisions instead of providing an overall pixel-based heatmap.”
“If this commentary can shift the focus even slightly from the basic assumption underlying most work in explainable ML—which is that a black box is necessary for accurate predictions—we will have considered this document a success,” she writes. “If this document can encourage policy makers not to accept black box models without significant attempts at interpretable (rather than explainable) models, that would be even better.”
PREVIOUSLY
AI HACKS
https://spectrevision.net/2021/08/02/ai-hacks/
MACHINE LEARNING ANIMAL BEHAVIOR
https://spectrevision.net/2019/10/07/open-source-neural-networks/
ARTIFICIAL SYNAPSES
https://spectrevision.net/2018/01/26/artificial-synapses/
SARCASM RECOGNITION
https://spectrevision.net/2016/02/11/sarcasm-recognition/
MACHINES NOW SMART ENOUGH to FLIRT
http://spectrevision.net/2007/05/17/machines-now-smart-enough-to-flirt/
