
“Cal Fire tanker 70 makes a fire retardant dump battling the Springs Fire in the Moreno Valley area Friday, April 3, 2026, in Riverside County, Calif.”
in WILDFIRE SUPPRESANTS
https://courthousenews.com/forest-service-fire-retardant-study.pdf
https://courthousenews.com/heavy-metals-in-aerial-fire-retardant
Forest Service pressed over heavy metal content in aerial fire retardant
by Monique Merrill / July 28, 2026
“A nonprofit comprising U.S. Forest Service employees concerned about the environment faced off with the Forest Service in federal court Tuesday, urging a judge to make the agency take another look at the ecological effects of heavy metals in fire retardant. ŌĆ£This case is largely about an undisputed point, which is that the agencies did not analyze heavy metals in the challenged consultation,ŌĆØ said Timothy Bechtold, attorney representing the environmental nonprofit. Forest Service Employees for Environmental Ethics┬Āsued the Forest Service, the U.S. Fish and Wildlife Service and the National Marine Fisheries Service in U.S. District Court for the District of Montana in 2025.
The Forest Service authorizes nationwide aerial application of long-term fire retardant across millions of acres of federal land as part of its efforts to combat wildfires. The nonprofit accused the agencies of violating the Endangered Species Act through the use of such aerial fire retardants laced with toxic heavy metals, which the group claims the agency neglected to properly assess or analyze. Senior U.S. District Judge Donald Molloy, a Bill Clinton appointee, questioned whether the Forest Service was privy to the exact chemical makeup of the fire retardants or if it was subject to trade secret protection from the manufacturers. Both sides confirmed the Forest Service was aware of the full list of ingredients.
The nonprofit, however,┬Āclaimed a Forest Service employee informed it that the agency had not disclosed its knowledge of toxic metals in the compound and declined to test them. ŌĆ£The agency was aware that there were toxic metals in the Phos-Chek formulations before they put out the biological assessment and while they were putting out the biological assessment, it just never made it into the biological assessment for, I assume, political reasons, but I donŌĆÖt know that,ŌĆØ Bechtold said. The Forest Service consulted with the Fish and Wildlife Service and the National Marine Fisheries Service to ensure the application of aerial fire retardant isnŌĆÖt likely to jeopardize endangered species or adversely impact critical habitat.
Those two agencies released biological opinions in 2022 and 2023, concluding the fire retardant program wouldnŌĆÖt jeopardize listed species, but the nonprofit claims the two agencies werenŌĆÖt given the full information about heavy metals. ŌĆ£We can say the agency knew that there were toxic metals in the formulation, and they just chose not to deal with them,ŌĆØ Bechtold said. ŌĆ£What we would like the Forest Service to do is to officially reinitiate consultation with the wildlife agencies.ŌĆØ ŌĆ£I think the evidence before the court is significant enough to show that they donŌĆÖt need to analyze whether reinitiation is required. They should simply reinitiate,ŌĆØ Bechtold said.
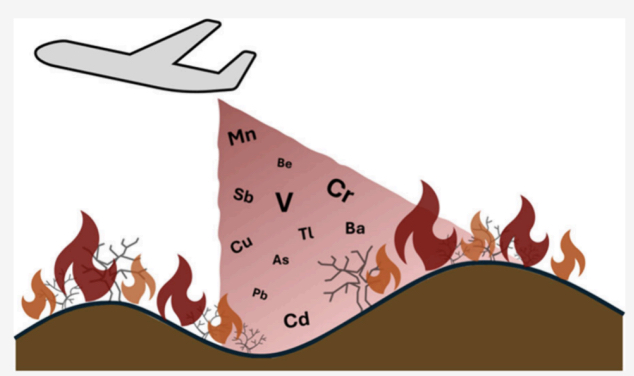
That evidence includes a┬Ā2024 study on metals in wildfire suppressants in which researchers disclosed aerial fire retardants contain vanadium, chromium, manganese, copper, arsenic, cadmium, antimony, barium, thallium and lead at concentrations four to 2,880 times greater than drinking water regulatory limits. The nonprofit claimed the agency has known about the presence of those metals in aerial fire retardant but didnŌĆÖt disclose their concentration or presence to either wildlife agency, resulting in their omission from the biological opinions. The Forest Service┬Āargued it had in fact given both wildlife agencies a complete list of every ingredient in each of the aerial fire retardants during consultation.
It also argued the study detailing heavy metals in aerial fire retardants the nonprofit relied on came out years after the agencies had completed their analysis. ŌĆ£In doing the consultation, the services used the best available science to determine the effects on the said species, and thatŌĆÖs really all that they are required to do. ThatŌĆÖs all that they could do here,ŌĆØ said Justice Department attorney Bonnie Ballard. ŌĆ£There was no information indicating that there were heavy metals in those formulas that were submitted.ŌĆØ But Molloy questioned the Forest Service about an incident referenced in the 2024 study in which the Washington Department of Ecology cited the Forest Service for multiple waste discharge permit violations for exceeding allowable metal concentrations relating to the storage of fire suppressants at an air tanker base.
Ballard stated it is not uncommon for heavy metals to be found after wildfires have occurred. ŌĆ£I can imagine that it was hard to know exactly where the heavy metals were coming from in that specific instance,ŌĆØ Ballard said. ŌĆ£I donŌĆÖt have knowledge of that situation.ŌĆØ ŌĆ£ŌĆŖYeah, but isnŌĆÖt the whole point of this that if there are chemicals being used and if thereŌĆÖs a reference for the biological assessment, that you want an accurate biological assessment, which as I understand it, includes analyzing each of the ingredients in those fire retardants and how they impact water life, plants, endangered species, other species?ŌĆØ Molloy asked. ŌĆ£And if thereŌĆÖs heavy metals that are not accounted for, does that mean the biological assessment is faulty?ŌĆØ
The Forest Service argued the best available science was used at the time of the consultation and that the agencies canŌĆÖt be expected to anticipate every possible finding that may be made in the future. Plus, if the agency canŌĆÖt determine if there are effects not previously considered, it doesnŌĆÖt trigger reinitiation. Molloy seemed skeptical. “I may sound like DOGE people, but sometimes the bureaucratic functioning ŌĆö if you have the information, why not reinitiate?ŌĆØ Molloy asked. ŌĆ£And then you get the answer, and you donŌĆÖt have wasted effort time, and you get good science.ŌĆØ Even if Molloy sides with the nonprofit, the agency argued the court should not vacate the biological opinions due to the disruptive consequences. Molloy indicated he would have an opinion out relatively soon.”
the CASE for LETTING MALIBU BURN
https://spectrevision.net/2018/11/15/the-case-for-letting-malibu-burn/
SURVIVING the PYROCENE
https://spectrevision.net/2020/09/11/surviving-the-pyrocene/
PYROCUMULUS CLOUDS
https://spectrevision.net/2021/07/22/pyrocumulus-clouds/
WILDFIRE MICROBIOLOGY
https://spectrevision.net/2023/06/28/pyroaerobiology/
FIRELESS WORLDS
https://spectrevision.net/2023/08/25/fireless-worlds/
WILDFIRE SEASON
https://spectrevision.net/2024/11/14/wildfire-season/
